무선 커넥티비티와 스마트 센싱 기술·통합 IP솔루션 분야 전문업체인 CEVA는 인공지능 및 머신러닝(AI/ML) 추론 워크로드를 위한 최신 프로세서 아키텍처 NeuPro-M(뉴프로-M)을 13일 발표했다. NeuPro-M은 광범위한 엣지 AI(Edge AI)와 엣지 컴퓨팅(Edge Compute) 시장을 대상으로 하는 독립적인 이종 아키텍처다.
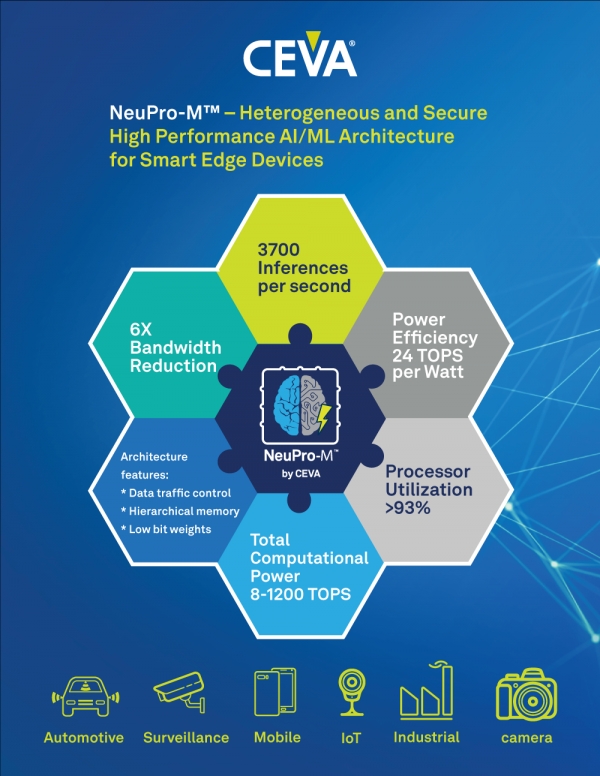
심층 신경망의 다양한 워크로드를 동시에 원활하게 처리하는 다중의 특화 코프로세서(co-processor)이자, 설정 변경이 가능한 하드웨어 가속기로 이전 모델 대비 하드웨어의 성능을 5-15배 향상시킨다. 또 업계 최초로 시스템온칩(SoC)과 이종 시스템온칩(HSoC)의 확장성을 모두 높이고 최대 1200TOPS(초당 10조회의 연산 속도)에 달하는 성능을 발휘하는 것은 물론, 강력한 보안 부팅 및 엔드 투 엔드(end-to-end) 데이터 개인 정보 보호 옵션을 제공한다.
NeuPro-M 프로세서는 NPM11 - 1.25GHz에서 최대 20TOPS에 달하는 단일 NeuPro-M 엔진과 NPM18 - 1.25GHz에서 최대 160TOPS에 달하는 8개의 NeuPro-M 엔진으로 우선 배포될 예정이다.
최첨단 성능을 지닌 단일 NPM11 코어는 ResNet50 신경망(convolutional neural network, CNN)을 처리할 때, 이전 모델에 비해 성능은 5배 향상시키고 메모리 대역폭은 1/6로 감소시켜 와트당 최대 24TOPS의 탁월한 전력 효율을 제공한다.
이전 모델의 뛰어난 성능을 기반으로 설계된 NeuPro-M은 기존의 모든 신경망 아키텍처를 처리한다. 뿐만 아니라 변압기, 3D 콘볼루션(convolution), 셀프 어텐션(Self-attention) 및 모든 유형의 순환 신경망(recurrent neural networks, RNN)과 같은 차세대 네트워크에 대해 준비가 되어 있으며, 250개 이상의 신경망과 450개 이상의 AI 커널 및 50개 이상의 알고리즘을 처리하는데 최적화됐다. 또 내장형 벡터 프로세싱 유닛(VPU)은 새로운 신경망 토폴로지와 AI 워크로드의 발전에 대해 미래에 사용 가능한(future proof) 소프트웨어 기반의 지원을 보장한다. 특히 CDNN(CEVA Deep Neural Network) 오프라인 압축 툴은 정확도에 미치는 영향을 최소화하면서 일반적인 벤치마크에 대해 NeuPro-M의 FPS/와트를 5-10배까지 높인다.
NeuPro-M 이종 아키텍처는 기능별 코프로세서와 부하 균형 기법(load balancing mechanism)으로 구성되며, 이전 아키텍처 대비 성능과 효율성을 향상시키는 데에 큰 도움을 준다. 먼저 제어 기능을 로컬 컨트롤러에 분산시키고 로컬 메모리 리소스를 계층적 방식으로 실행함으로써 데이터 흐름의 유연성을 높였다. 이에 따라 활용률은 90% 이상을 넘었으며 주어진 시간에 서로 다른 코프로세서와 가속기가 데이터 부족으로부터 안심할 수 있게 됐다. 또 CDNN 프레임워크에 의해 특정 네트워크, 원하는 대역폭, 사용 가능한 메모리 및 목표 성능에 쓰이는 다양한 데이터 흐름 체계를 실행함으로써 최적의 부하 균형을 달성할 수 있게 됐다.
◆NeuPro-M 아키텍처 주요 기능은 다음과 같다.
• 2-16비트의 다양한 정확성을 갖춘 4K MACs(Multiple And Accumulates)으로 구성된 메인 그리드 어레이
• Weights 및 activations를 위한 위노그라드(Winograd) 변환 엔진의 탑재로 콘볼루션 시간을 ½로 단축하고, 정밀도 저하가 0.5% 미만인 8비트 콘볼루션 프로세싱 가능
• 희소성(Sparsity) 엔진을 통해 제로 밸류(zero-value)를 갖는 layer별 weights 혹은 activations 작업을 생략하여 최대 4배의 성능을 향상시킴과 동시에 메모리 대역폭과 전력 소비량을 감소
• 새로운 신경망 아키텍처는 32비트의 부동 소수점(Floating Point)에서 2비트 이진신경망(Binary Neural Networks)에 이르는 모든 데이터 유형을 지원. 이를 처리하는 완전하게 프로그래밍할 수 있는 벡터 프로세싱 유닛
• 메모리 대역폭을 절감하기 위해 메모리를 저장하는 동안 가변적 Weight과 데이터 압축으로 2비트까지 낮추고, 데이터를 읽는 동안 실시간 압축 해제 가능
• 외부 SDRAM으로 데이터를 전송하는데 소비되는 전력을 최소화하도록 동적으로 구성된 2단계 메모리 아키텍처